
One month as a procrastinator on Stack Overflow
Hello everyone, I’m 6103040 aka F. Privé. In this post, I will give some insights about answering questions on Stack Overflow (SO) for a month. One of the reason I’ve began frenetically answering questions on Stack Overflow was to procrastinate while finishing a scientific manuscript.
My activity on Stack Overflow
We’ll use David Robinson’s package stackr to get data from Stack Overflow API.
# devtools::install_github("dgrtwo/stackr")
suppressMessages({
library(stackr)
library(tidyverse)
library(lubridate)
})Evolution my SO reputation
myID <- "6103040"
myRep <- stack_users(myID, "reputation-history", num_pages = 10)
(p <- myRep %>%
arrange(creation_date) %>%
ggplot(aes(creation_date, cumsum(reputation_change))) %>%
bigstatsr:::MY_THEME() +
geom_point() +
labs(x = "Date", y = "Reputation",
title = "Evolution of my SO reputation over time"))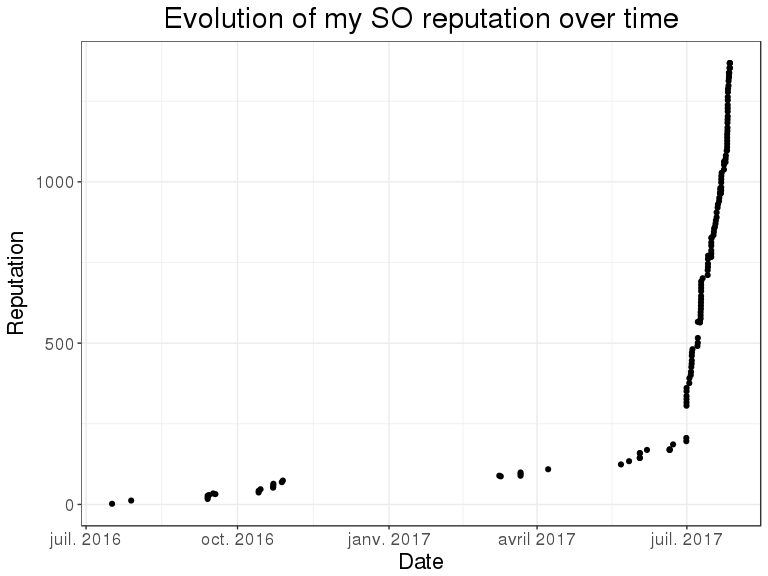
p +
xlim(as.POSIXct(c(today() - months(1), today()))) +
geom_smooth(method = "lm") +
ggtitle("Evolution of my SO reputation over the last month")## Warning: Removed 39 rows containing non-finite values (stat_smooth).## Warning: Removed 39 rows containing missing values (geom_point).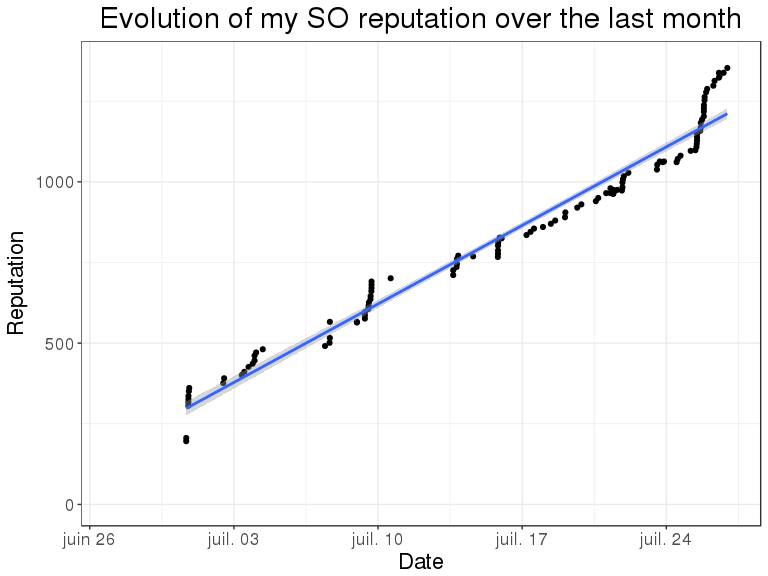
Analyzing my answers
(myAnswers <- stack_users(myID, "answers", num_pages = 10,
fromdate = today() - months(1)) %>%
select(-starts_with("owner")) %>%
arrange(desc(score)) %>%
as_tibble())## # A tibble: 63 x 7
## is_accepted score last_activity_date creation_date answer_id
## <lgl> <int> <dttm> <dttm> <int>
## 1 FALSE 9 2017-07-17 11:07:14 2017-07-16 22:21:05 45132967
## 2 FALSE 5 2017-07-25 09:27:02 2017-07-25 09:27:02 45296612
## 3 FALSE 5 2017-07-09 08:27:24 2017-07-09 08:27:24 44993632
## 4 TRUE 4 2017-06-30 18:57:23 2017-06-30 18:56:04 44851544
## 5 FALSE 3 2017-07-09 11:15:17 2017-07-09 11:15:17 44994826
## 6 TRUE 3 2017-07-02 10:27:29 2017-07-02 10:27:29 44868837
## 7 TRUE 2 2017-07-25 19:44:33 2017-07-25 19:44:33 45310305
## 8 TRUE 2 2017-07-25 15:41:12 2017-07-25 15:41:12 45305138
## 9 TRUE 2 2017-07-23 12:55:24 2017-07-23 12:55:24 45264278
## 10 TRUE 2 2017-07-21 20:50:42 2017-07-21 20:13:12 45244205
## # ... with 53 more rows, and 2 more variables: question_id <int>,
## # last_edit_date <dttm>So it seems I’ve answered 63 questions over the past month. Interestingly, my answers with the greatest scores were not accepted. You can get a look at these using
sapply(c("https://stackoverflow.com/questions/45045318",
"https://stackoverflow.com/questions/45295642",
"https://stackoverflow.com/questions/44993400"), browseURL)The first one is just translating some R code in Rcpp. The two other ones are dplyr questions.
myAnswers %>%
group_by(score) %>%
summarise(
N = n(),
acceptance_ratio = mean(is_accepted)
)## # A tibble: 8 x 3
## score N acceptance_ratio
## <int> <int> <dbl>
## 1 -2 1 0.0000000
## 2 0 32 0.3125000
## 3 1 14 0.4285714
## 4 2 10 0.7000000
## 5 3 2 0.5000000
## 6 4 1 1.0000000
## 7 5 2 0.0000000
## 8 9 1 0.0000000My acceptance rate is quite bad.
Some insights from this experience
purrr is badly received as a proxy of base R functions such as
sapplyandlapply(https://stackoverflow.com/questions/45101045/why-use-purrrmap-instead-of-lapply)People tend to use dplyr where base R functions are well-suited:
- https://stackoverflow.com/questions/45244063/using-dplyr-to-replace-a-vector-of-names-with-new-names
- https://stackoverflow.com/questions/45243363/dplyr-to-calculate-of-prevalence-of-a-variable-in-a-condition
- https://stackoverflow.com/questions/44881723/replace-column-by-another-table
- https://stackoverflow.com/questions/44995997/create-a-new-variable-using-dplyrmutate-and-pasting-two-existing-variables-for
- https://stackoverflow.com/questions/45309455/mean-function-producing-same-result
To avoid basic issues, I find very important to know base R classes and their accessors well (you just need to read Advanced R)
The tidyverse solves lots of problems (you just need to read R for Data Science)
Guiding to a solution is much more fun than just giving it (https://stackoverflow.com/questions/45308904).
Conclusion and bonuses
I think it has been a good experience to answer questions on SO for a month.
I’m proud of this algorithm written only with dplyr that automatically get you a combination of variables to form a unique key of a dataset. Also, I wanted to make a blog post about good practices for parallelization in R. I’m not sure how to do it and which format to use, but, for now, you can get some good practices in one of my answer. Finally, if you miss the previous infinite printing of a tibble, you can get a workaround there.